How do LLMs work ?
Introduction: What Are LLMs?
Large Language Models (LLMs) are AI systems that generate text by predicting the next word starting from a given input sequence, kind of like a super-smart autocomplete. They have been trained on massive amounts of text, so they can continue a sentence or answer a question in a very human-like way. Popular examples of LLMs include OpenAI’s ChatGPT, Google’s Bard, Meta’s LLaMA, and Anthropic’s Claude. These models power many applications we use today – from chatbots and language translators to coding assistants and content creation tools. In short, an LLM can take a prompt (the text you give it) and then predict the most likely or sensible way to continue that text.
For example, if you start a sentence with "The weather is", an LLM will analyze its training data and predict that you most likely intend to say "cold." It chooses the word "cold" because in its training, the phrase "The weather is cold" appeared often, making "cold" a high-probability continuation. The image below illustrates this process – the model looks at the prompt "The weather is" (broken into tokens) and calculates the probabilities of possible next words, with "cold" being the most likely choice.
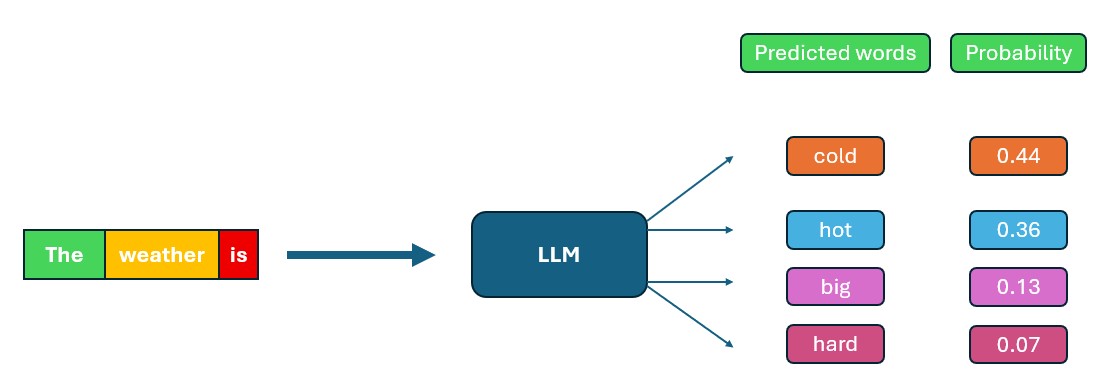
Figure: An LLM predicting the next word for the prompt "The weather is ...". The model assigns a higher probability to "cold" as the continuation, yielding the sentence "The weather is cold".
How Do LLMs Learn Language? (Training Process)
LLMs don’t come out of the box knowing English or any language – they learn through a training process involving several steps:
a. Collecting Data
First, the AI is “fed” an enormous amount of text. This includes books, Wikipedia articles, websites, chat logs – basically, a huge swath of the internet and libraries. By reading these millions of examples, the LLM builds up a statistical picture of language: it learns which words tend to follow which others, how sentences are structured, and so on.
b. Breaking Text into Small Pieces (Tokenization)
The raw text is too much for the model to handle as-is, so it gets broken down into small pieces called tokens. Tokens are like the puzzle pieces of language: they might be whole words, parts of words, or even single characters. For example, "Hello, world!" might be tokenized into ["Hello", ",", "world", "!"]. The model can’t actually “understand” text, but it can work with numbers – so each token is mapped to a number. Think of tokenization as chopping a sentence into Lego blocks or puzzle pieces that the model can play with.
c. Learning Through Prediction (Pretraining)
Now the LLM begins its core training by playing a giant game of fill-in-the-blank. It tries to predict the next token (or word) in every sentence it reads. For instance, it sees the phrase "The weather is ___" and tries to guess "cold." If it gets it wrong, the model adjusts its internal settings (parameters) to improve. By doing this prediction millions of times, the LLM gradually learns the patterns of language. In essence, the model is pretrained to minimize its mistakes in guessing the next word. Over time, it becomes very good at producing likely continuations for any given text prompt.
d. Fine-Tuning for Specific Tasks
The pretrained model is like a general language engine. The next step is fine-tuning it for specific uses. Developers train the LLM further on narrower datasets tailored to a task. For example, to create a chatbot, they fine-tune the model on example conversations and answers. To get an LLM that helps with coding, they fine-tune it on programming-related text. This step teaches the model to not just continue text, but to follow instructions and give relevant outputs. For instance, OpenAI took a base model and fine-tuned it on question-answer pairs so that it would respond directly to questions with an answer, rather than just rambling on. Fine-tuning basically adjusts the model’s behavior for whatever application it’s intended for (dialogue, summarization, translation, etc.).
e. Human Feedback to Improve Responses
Even after fine-tuning, the AI’s answers might be correct but awkward, or sometimes just off the mark. To polish the model, humans get in the loop. In a process often called Reinforcement Learning from Human Feedback (RLHF), people examine the AI’s outputs and provide feedback on which answers are good and which are not. For example, the model might generate several possible answers to a prompt; human reviewers rank these or point out flaws. The model then uses this feedback to adjust itself, so it leans toward responses that people prefer. This step is like a coach refining an already skilled player – it helps the LLM sound more natural, follow instructions better, and avoid obvious mistakes or inappropriate content.
How LLMs See Words (Embeddings)
When you talk to an LLM, it doesn’t literally understand words the way we do. Instead, it converts each word (or token) into a bunch of numbers. This numeric representation is called an embedding. You can imagine an embedding as a vector in a high-dimensional space (think of a very complex coordinate system). The magic is that words with similar meanings end up having embeddings that are close to each other in this space.
For example, if the model has learned from lots of sentences that "town" and "city" often appear in similar contexts, it will represent "town" and "city" with vectors (lists of numbers) that are very close together. On the other hand, a very unrelated word like "rocket" would be far away from "town" in this vector space. This way of “seeing” words as numbers allows the LLM to detect similarities and relationships between words. It’s like a color wheel for language – words with similar meanings are clustered together, just as similar shades of color appear side by side on a color wheel. So, an LLM knows that "big" is close to "large", and far from "tiny,” not because it knows the dictionary definitions, but because those words turned out to be used in similar ways in the training text, and thus have similar embeddings.
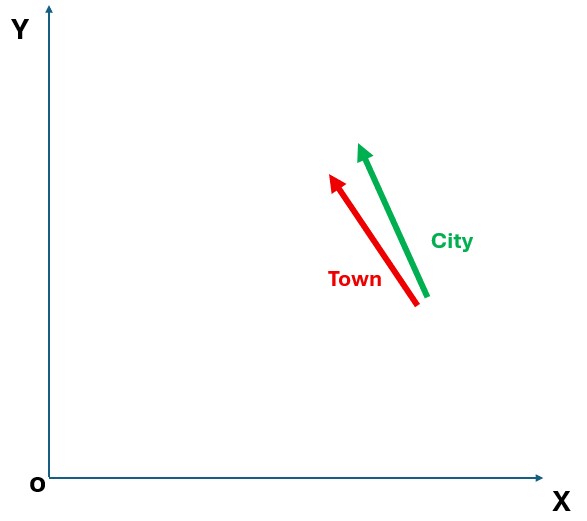
Figure: A simple illustration of word embeddings: similar concepts cluster together in the model’s "word space." In a trained LLM, words like "Town" and "City" might be located near each other, reflecting their related meaning. (In a real model, this space has hundreds or thousands of dimensions!)
How LLMs Focus on Important Words (Attention)
When generating text, LLMs use a mechanism called attention to figure out which words in the input are most important to consider. Think of attention as a spotlight that the model can shine on certain parts of the text. Instead of treating every word equally, the model learns to weigh them differently: it gives more weight to the words that are most relevant to the task at hand, and less to others. In technical terms, it calculates attention scores that indicate how much each word should “pay attention” to the other words in the sentence.
This concept is akin to highlighting key words in a sentence – just like you might highlight clues in a mystery novel. For example, in the question “Where is the Eiffel Tower located?”, an LLM will place high attention on “Eiffel Tower” and “located” because those words are crucial to determining that the answer should be “Paris, France.” The model doesn’t literally know meanings, but through training it learned that “Eiffel Tower” in a question signals that the location (Paris) is the likely answer, so it focuses on that.
Attention allows the model to dynamically adjust its focus as it generates or interprets text, making sure it’s looking at the words that matter most. By using attention, the LLM can handle long sentences or paragraphs and figure out dependencies – for instance, resolving what a pronoun refers to, or which parts of a sentence inform the next word choice. In short, attention is the LLM’s way of zeroing in on the relevant bits of text, much like our brain might home in on the critical clues in a story.
How LLMs Put Everything Together (Transformers)
Transformer is the name of the neural network architecture that combines the tokenization, embeddings, and attention mechanisms to make the whole system work. Introduced in a 2017 research paper titled “Attention Is All You Need,” the Transformer architecture revolutionized how AI handles language. Prior models (like RNNs – Recurrent Neural Networks) processed text sequentially, meaning they looked at one word at a time in order. Transformers do things differently: they look at the entire sequence at once and process words in parallel.
This parallel processing is a bit like solving a jigsaw puzzle by examining all the pieces spread out on the table, rather than assembling the puzzle one piece at a time. Because of attention, the Transformer can still understand the order of words (it adds a bit of positional information to each token to keep track of sequence), but it doesn’t have to wait and go word-by-word. Each word’s embedding flows through the network alongside the others simultaneously, and attention layers let every word consider every other word. This makes the model much faster and more effective at capturing context.
The Transformer architecture uses multiple layers of attention and other computations (like feed-forward neural networks) to gradually build an understanding of the text. By the end of this process, the model can generate a coherent output.
In simpler terms, the Transformer lets the model look at all aspects of a sentence at once, understanding context from the whole sentence rather than just from left-to-right processing. This is why modern LLMs can handle long and complex inputs so well – they can, for instance, see the beginning and end of a paragraph together to decide how to respond. Transformers are the engine under the hood that made today’s LLMs possible, enabling that powerful combination of parallel processing and attention to context.
Conclusion
LLMs like ChatGPT and Bard are incredibly powerful at generating human-like language, but it’s important to remember that they operate on patterns and probabilities, not true understanding. An LLM doesn’t know facts or have beliefs – it statistically predicts what words should come next based on its training. In essence, it’s an expert at mimicking language it has seen before, a sophisticated pattern-matching machine.
This means that while LLMs can produce very convincing and contextually relevant text, they can also occasionally produce incorrect or nonsensical answers (often called “hallucinations”) if the prompt leads them astray. They also inherit biases present in their training data, which can lead to biased or undesirable outputs if not carefully managed.